appreciate在南师的日子。
GIS与RS的囧境
缺地,少人
缺少地理认知、不能很大程度上的符合地理现象,缺少与人的交互作用,死气沉沉!🏝
界限模糊
陷入了传统基础学科与工具学科的模糊界限。
当GIS作为工具学科的时候,它就必须主动地或是被动地迎接新的技术、新的趋势,更为具体的就是云计算、雾计算、边缘计算、并行计算、人工智能、大数据、VR\AR等概念。 这是工具学科无法避免的情况,必须时刻拥抱新的未来。
但是当GIS作为理论学科的时候,这又要求我们以地理学的认知来寻找答案,这意味着:
- 如何抽象世界
- 将抽象的世界以信息的方式如何进行存储
- 信息的分析、模拟与预测 这就是理论学科的意义,GIS是推演,而不是简单的反演。
地理思想
即考虑 区域与分异 ,这意味着发展本地区域优势,多区域协同发展。
空间相关性-地理学第一定律
地物之间的相关性与空间距离有关,一般来说,距离越近,地物间相关性越大;距离越远,地物间相异性越大。
空间异质性-地理学第二定律
空间的隔离,造成了地物之间的差异,即差异性。具体分为 空间局域异质性和空间分层异质性,前者是该点属性值与周围不同;后者是指多个区域之间互不相同。
论文写作
文中不能出现不确定的概念,自创的概念。
论文应该是普通人的故事,因为你不能避免你的读者是专业领域的人。这就要求详细的、科普性的文章。
入手要窄(能做),价值要高(有意义做)。
论文应当是 传承+延申 ,一方面要强调前人的工作,另一方面要在形式、内涵上有所提升。
论文是科学问题的凝练和阐述。 那么什么是科学问题呢?是人类认知的缺陷与错误。 如何进行凝练?建立知识体系树,具体来说就是分类,再分类,逐个论述,描述其特点,缺点以及如何被下一个方法进行了改进。 如何进行阐述? A)发展法 指针对目前最好的办法也无法解决问题。 1.目前的几类方法 2.每类是什么、如何做、要求和缺点,从简单、低精度到复杂、高精度进行阐述 3.上述方法无法解决问题的原因 4.引出自己的方法 B)重点法 对现有方法的改进。 1.目前的积累方法 2.一一阐述 3.你的方法的特别,潜力?普遍性? 4.对方法进行展开、分析、找到根源,突出研究意义。
结构
1.研究背景之下的重点、热点、要点(用于限制2点的范畴) 2.阐述现有的认知体系(描述研究现状,建立知识体系树) 3.描述其中的科学问题,找出问题的机理(appreciate but point that your research is important!) 4.该篇文章的目的和组织结构。
OpenGMS的Open
开放的思想,应当分为两个部分,一份部分是资源的open,另一部分是社区的open。
- 资源
- 数据的Open
- 模型、知识的Open
- 社区 在资源开放的基础上,协作、共同解决问题的求解平台。
OpenGMS的Data
背景
现代计算机技术依赖于冯·诺依曼架构,数据和算法分离存储,互相依赖。这也决定了任何地理模型的集成和运行最终都是模型程序和模型数据的耦合和连接。具体来说就是流程控制逻辑和数据配置逻辑。 流程控制逻辑主要是负责对建模场景中模型之间的关系进行调配,利用顺序、循环、嵌套等环节来加以控制。 数据配置逻辑主要是负责对模型运行所需的数据资源进行调配,在模型与数据的对接、模型与模型之间的数据交换等环节来进行配置。
配置模型服务和数据资源的连接,目前采取的都是个案(固定的数据格式),缺乏一个通用的数据集成基础,从而使所构建的集成建模场景严格依赖于初始设定的数据资源,难以支撑在开放网络环境中进行探索式、可配置的模型-数据资源对接,也制约了建模个案研究成果的累积式集成,使得耗费大量精力构建的集成建模情景难以作为可重用的资源进行共享。
为了在地理模型的集成领域中,将“模型服务集成的流程控制逻辑”和“模型服务运行的数据配置逻辑”进行有机解耦,使得两者在分布式地理模型集成应用过程中协调工作的同时,能够在各自内部独立深化发展。我们引入了模型容器和数据容器。
数据容器简化了地理模型服务集成的数据配置、处理和调度的工作。
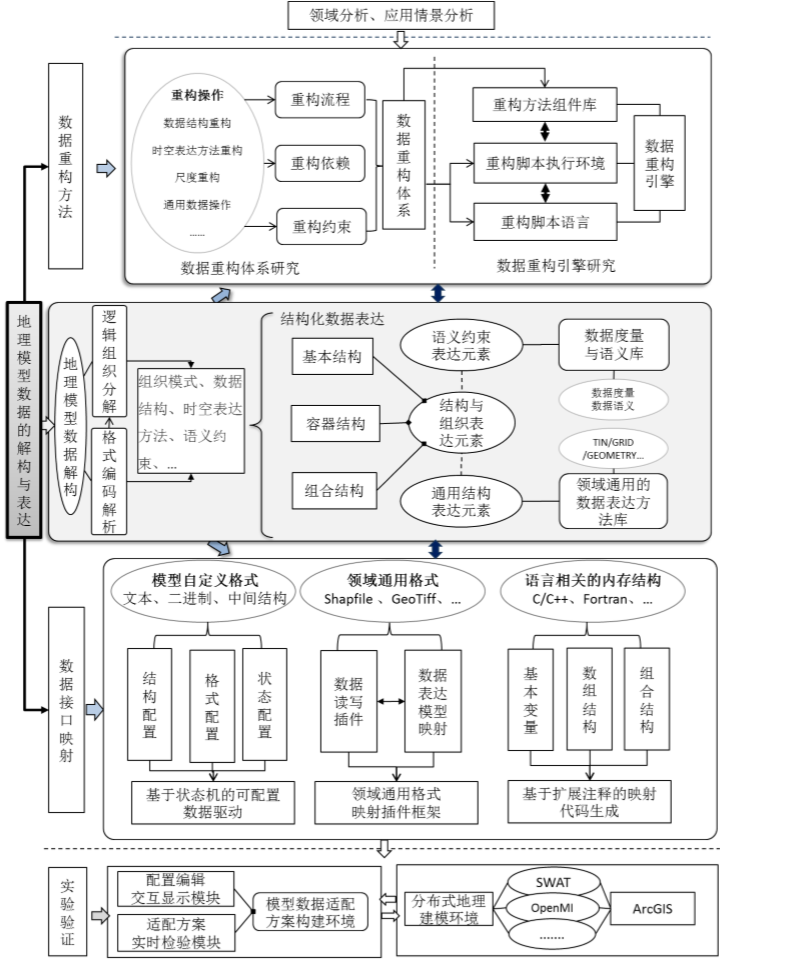
技术路线中涉及到 3 个部分。
- 地理模型数据的结构化表达模型是基础,它的目标是通过归纳、提炼和总结,获取具有装配组合能力的数据表达元素和组合机制;
- 数据重构方法研究从数据的逻辑组织层面来对地理数据进行各种重构操作。
- 数据接口映射研究解决模型输入、输出的原始数据与结构化表示模型之间的映射问题
UDX
针对地理模型的数据,我们发现存在两个问题。
- 首先,地理模型所涉及到的输入/输出/控制数据的异构特征增加了数据资源组织与管理的不确定性;
- 其次,数据在地理模型中往往代表了物质流、能量流和信息流的交换,传统的以特点数据格式来代表的方法,难以在支撑模型合理运行方面保证数据内容的无损传输。
为了解决以上的问题,OpenGMS 团队提出了 UDX(统一数据表达-交换模型)。UDX 旨在为面向地理模型服务与异构数据资源对接的数据规格描述方法,地理模型服务化集成应用提供一致的数据视图,一致的数据视图是连接异构资源和模型服务的通信基础。
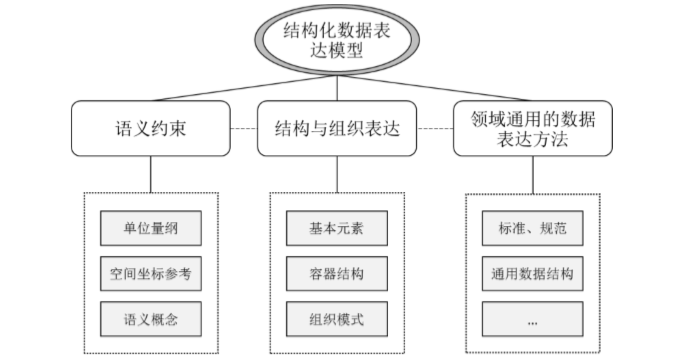
UDX 涉及两个实现:一个是统一数据表达的 UDX Schema,还有一个是统一数据交换的 UDX Data,两者共同构成了统一数据表达-交换模型的内容。注意这两者的结构层次是同构的。UDX Schema 负责对模型数据内容进行详尽的描述,包括地理模型数据规格在形式和结构层面的描述;UDX Data 则是严格匹配于 UDX Schema 的具体数据内容。
除了形式和结构层面的描述以外,UDX 统一数据表达交换模型中还包含了相应的语义概念信息、空间参考信息、单位量纲信息和数据表达通用模板信息。通过将这些信息附加到特定的节点 Node 上,可以对地理模型数据进行完备的描述,提供既支持计算机识别的结构化信息,也易于研究者理解数据内含的语义信息。
基于 UDX 的统一数据交换
我们往往会遇到这样一个情况,在模型程序实现的源代码实现方面,不同的模型开发者往往采用不同的底层数据结构来支撑上层的逻辑计算。
当我们并没有指定的数据时,我们往往只能采用直接的数据交换策略:
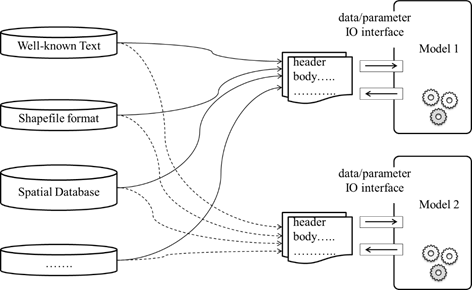
而由于地理模型在问题领域、时空尺度、建模方法、实现方式、运行环境等方面的诸多差异,利用某个确定的数据结构在适用于某些地理模型的同时,也面临难以支撑其他地理模型的困难;尤其是面对大量已有的地理模型资源方面(通常称作为 Legacy Models),更是难以利用一个固定的数据结构来实现其数据接口。我们在大量模型的集成环境中需要做大量的数据预处理、转换、抽取等工作。
我们要注意虽然地理模型的数据接口在外观上表现出来的是某种格式的数据文件、某种类型的变量,但在内容上则是对特定信息的依赖。
无论是 WKT 形式的几何数据,还是 Shapefile 形式的数据,都可以通过数据信息的抽取向 Node-Kernel 结构中填充数据内容(也就是生成 UDX Data);更广泛的自定义格式的数据也可以通过此种方式实现统一的数据交换。
这样基于 UDX 的数据交换策略就有了:
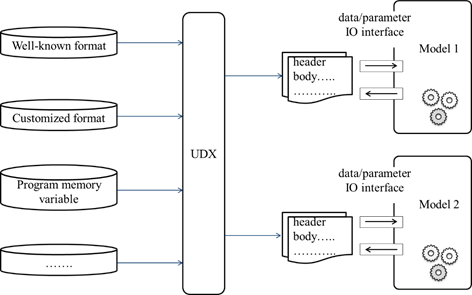
基于 UDX 的地理模型应用和集成运行,对于某个特定的地理模型而言似乎增加了数据处理的过程。 但在综合地理模拟中,涉及到多个不确定的地理模型之间的集成与运行,通过直接的数据格式转换虽然能够方便于某一个特定模型的运行,但对于整个集成模拟应用又造成了新的不便:
- 首先体现在广泛的自定义格式难以直接进行转换,模型使用者在不了解数据内容的前提下进行的数据转换往往具有尝试性,增加了模型使用的不便;
- 其次,模型相关的数据格式多种多样,同源的信息可以表现为异构的数据组织,孤立的数据转换难以避免重复的代码编写;
- 还有,异构地理模型的集成不仅仅只是对数据格式的简单转换,其中涉及到的大量信息的抽取和重构,特定数据格式支撑下的数据处理成果难以形成积累,也难以重用。
映射简介
数据映射,实现 UDX 与异构数据接口之间的双向转换。
映射实现原理
理想中,我们拥有三种策略,利用通过格式读取 API 定制,基于状态机的配置化映射,基于扩展语言注解的绑定代码生成。
(1) 基于插件的领域通用数据格式映射 虽然很多地理模型使用了自定义的数据模型和数据格式,但是依然有相当数量的模型依赖于一些领域内(往往是GIS领域)的通用数据格式,比如Shapefile、CAD、GeoTiff、NetCDF等。这些通用的数据格式往往提供了读写的API。因此针对常用是数据格式,我们可以提供定制式的插件。
(2) 基于状态机的配置化的文件格式映射机制 此种机制适用于未被插件格式支持的情形,用以应对大量的地理模型自定义文件格式,主要思路如下:任何数据文件的组织对应的都是内存数据结构的反应,而内存数据结构是由编程语言决定的,其模式是有限的。而状态机是一种在信息技术领域经典的设计模式。OpenGMS尝试使用状态机来实现配置化的文件格式映射机制。
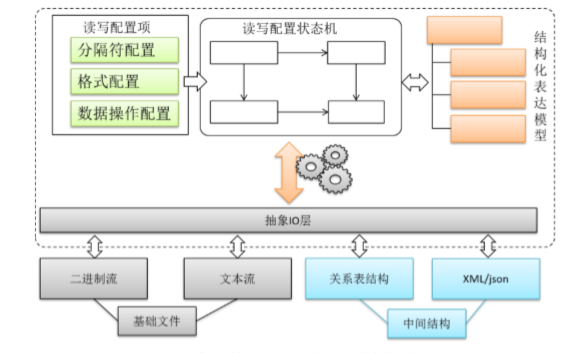
该方法包含两层抽象:
分隔符抽象,所有的文件都是由分隔符和数据元素组成的。分隔符决定了数据的读写控制,但是分隔符在不同的文件中又有所不同,比如文本文件中的Space,Tab,Enter,二进制文件中的数据类型长度,数据表中的字段,XML/JSON中的结点,因此不同的文件往往需要采取不同的读写方式。
状态机抽象,状态表明当前读写的位置,由数据的扫描过程驱动,分隔符决定事件,从而影响状态变迁,状态决定了需要采取的数据映射动作。
(3) 基于扩展语言注释的内存数据绑定代码生成 此情况适用于基于内存的数据传输,这种方式需要侵入数据接口的定义代码,通过在代码文件中引入扩展注释,通过扫描注释,自动地生成数据绑定代码。 一方面针对不同的语言,我们需要组织不同的扫描方式,另一方面要求使用者非常熟悉模型代码才能去添加扩展注释。(插嘴,很像java的注解)
映射现实
😿 然而现实是,通过格式读取 API 定制的映射我们实现了的都是寥寥无几。
而且对于那茫茫何其多的、何其复杂的地理模型数据,我们能做到的就是,定制写代码
1.MappingWraper 读取配置文件,通过反射加载 dll,获取类以及类中的方法。
2.dll 至少包含两个方法,分别是Src2Udx(inputPath,outputPath)与Udx2Src(inputPath,outputPath),以实现数据之间的转换。
映射配置文件
- cfg.xml 或 cfg.json 提供给模型容器使用的,找到 MappingWraper 所在的路径
<config>
<type>exe</type>
<start>MappingWraper.exe</start>
<schema>./schema.xml</schema>
</config>
{
"config": {
"type": "jar",
"start": "MappingWraper.jar",
"schema": "./schema.xml"
}
}
- cfg_map.xml 声明调用的 DLL,以及 DLL 里面的类与方法,以及MappingWraper中的其他指令信息。以供反射使用
<MappingMethodInfo name="Mapping.dll">
<Method action="-w" name="Udx2SrcRun" class="Mapping.csvConverter" description="Udx2SrcRun">
<Params datatype="System.String" type="in" name="srcFile" description="输入文件"/>
<Params datatype="System.String" type="out" name="outputFile" description="输出文件" schema="./udx_schema.xml" />
</Method>
<Method action="-r" name="Src2UdxRun" class="Mapping.csvConverter" description="Src2UdxRun">
<Params datatype="System.String" type="in" name="srcFile" description="输入文件" schema="./udx_schema.xml" />
<Params datatype="System.String" type="out" name="outputFile" description="输出文件" schema="" />
</Method>
<Method action="-h" name="help" description="帮助信息">
</Method>
<Method action="-v" name="version" description="版本信息">
</Method>
<Method action="-s" name="schema" schema="udx_schema.xml">
</Method>
<Method action="-c" name="cability" description="可访问的节点">
</Method>
</MappingMethodInfo>
映射 DLL
在创建好配置文件后,你需要创建一个 dll 库,并在里面定义类名和方法名,如下图所示:

映射使用方法
在准备好配置文件和DLL之后,将其拷贝到 MappingWrapper.exe 的同级目录下,输入对应的cmd命令后即可调用重构方法 :
MappingWraper.exe -r -f dd.tif -u rr.xml //src->udx flag=1
MappingWraper.exe -w -u dd.xml -f rr.tif //udx->src flag=0
映射部署方法
在准备好所有东西后,将其打包为Zip包,上传到数据容器即可。 最终的文件参考目录如下:

映射TODO
映射方法的理想实现暂时不考虑。
重构简介
重构,实现 UDX 在逻辑结构和内容层次的重构。是整个数据容器的核心环节。

重构操作涉及到: (a)结构层的数据重构。数据结构是数据模型和数据组织的映射,数据结构同时也会影响数据的 存储格式。结构层数据重构是最常见的重构方法,如矩阵行存储和列存储的变换,流场数据按(u, v) 组织与按(v, u)组织的转换。 (b)时空离散方法的转换。地理模型很多都有时空意义,而时空特征的表达往往依赖于一定的时 空离散方法。比如最常见的 GRID 和 TIN 表达的 DEM 之间的转换,就属于这种重构。时空离散方法 的转换又可能嵌套插值、平均值、数据的差分和积分等重构操作。 (c)时空尺度变换。地理模型的尺度相关性使得尺度上的不兼容同样影响模型运行,对数据进行 尺度上变换,即升尺度或者降尺度是常用的重构操作。如根据地形分析模型中对输入 DEM 数据的精 度要求,对用前所述地理数据表达模型表达的 DEM 数据进行空间重采样的数据重构。 (d)单位量纲与坐标系的变换。数据都具有确定的单位与量纲(甚至无量纲数据),只有与模型 要求的单位与量纲兼容,才能计算出正确的结果,对于空间数据的空间参考具有同样的含义,这也 是空间数据处理最常见的数据重构。 (e)数值计算重构。数据的值都具有一定的语义,比如流量、流速、温度。相同的地理现象可以 用不同的方式进行表达,比如由流速计算流量,用气压代替高度等。此时就需要通过一定的求值操作,对数据进行变换。
重构方法的组合、嵌套、顺序结构形成了重构的基本流程。重构流程将单个重构过程组合,实现了原始数据到目标数据的转换。
注意,上述的重构方法都是对于结构化数据表达模型所构建的操作。
重构实现原理
理想中,我们拥有大量的重构方法组件库提供重构功能、脚本语言描述重构逻辑、脚本执行器驱动方法对原属数据进行重构以产生目标数据。
结构化表达模型的层次化结构,决定了节点是其基本的数据组织单元。 脚本语言的关键操作逻辑包括:
- Select:实现对数据结点的遍历,是执行控制的起点;
- Filter:按条件对数据结点进行过滤;
- Assemble:用来实现遍历等操作结果的数据组装,构成新的结点结构;
- As[] :将选中结点的内容作为一个领域通用的数据结构(特定的UDX);
- Do :对选中的结点执行重构,重构由重构方法组件库提供,产生重构后的数据结点;
- Produce :生产操作,将Assemble和Do的结构聚合得到结构;
- To : 进行新的树结构的构造,To指明了装配的路径;

重构现实
😿 然而现实是,我们能做到的就是,写代码,跟映射一致的,也是通过反射实现整个方法。
RefactorWraper 读取配置文件,通过反射加载 dll,获取类以及类中的方法。
因此创建一个重构方法,需要配置文件,以及重构方法 DLL.
重构配置文件
- cfg.xml或cfg.json 提供给模型容器使用的,找到 RefactorWraper 所在的路径
<config>
<type>exe</type>
<start>RefactorWraper.exe</start>
<schema>./schema.xml</schema>
</config>
{
"config": {
"type": "jar",
"start": "RefactorWraper.jar",
"schema": "./schema.xml"
}
}
- cfg_refactor.xml 声明调用的 DLL,以及 DLL 里面的类与方法
<RefactorMethodInfo name="GridTest.dll">
<Method name="gridInvdist" class="GridTest.Grid" description="gridInvdist">
<Params datatype="System.String" type="in" name="srcFile" description="输入文件" schema="./udx_schema.xml" />
<Params datatype="System.String" type="out" name="outputFile" description="输出文件" schema="./udx_schema.xml" />
</Method>
</RefactorMethodInfo>
重构 DLL
在创建好配置文件后,你需要创建一个 dll 库,并在里面定义类名和方法名,如下图所示:

重构使用方法
在准备好配置文件和DLL之后,将其拷贝到 RefactorWrapper.exe 的同级目录下,输入对应的cmd命令后即可调用重构方法 :
RefactorWraper.exe methodName params...
重构部署方法
在准备好所有东西后,将其打包为Zip包,上传到数据容器即可。 最终的文件参考目录如下:

重构TODO
数据容器(服务总线)
地理模型的分布式集成应用过程中,对于支撑模型运行的数据资源配置工作必然涉及到具体网络节点之间的访问。单个模型服务的调用、多个模型服务的集成,以及参数调优和可视化分析等工作,都需要建模者进行频繁且大量交叉的数据资源配置。因而,在地理模型数据服务总线中,为集成建模任务提供统一的数据资源管理功能,是降低数据资源请求分发难度的重要内容。
其中服务总线一方面要提供特定的数据资源(该资源的全部实体或者部分特定信息,及抽取),另一方面也要提供相关的数据准备工作(映射,重构)。
负责将分散的模型数据资源进行统一的管理,为集成建模任务中的每个模型服务配置合适的数据资源,根据地理模型数据规格的服务化接口,响应数据请求和进行数据分发。
以参与式建模任务为使用情景,必须从模型执行端和数据资源访问端考虑数据配置工作。 数据服务控制模块旨在访问数据资源,在数据服务控制模块中,每个相关的数据资源都被分配了一个数据存根 Data Stub(Link configuration);数据存根用于帮助参与建模者处理从模型服务控制模块路由的数据
地球龟裂
真理往往无论在微观理论、宏观理论、现实意义中往往都能得到体现。(往往存在跨尺度的优良表现)
