2017/06-2018/06 走马上任,就开始CVM了。
门户
初始MVC架构:其中view是由HTML控制的,是一种前后端分离开发的模式
- html/js/css
- ajax+@WebServlet
- service
- dao
- MongoDB
数据容器
属于后台渲染
- ejs
一个模板语言,帮你利用普通的javascript代码生成HTML页面。可以把它理解成nodejs中的JSP文件。
- nodejs
- express框架
Geoserver
-
源码解析 作为一个JavaWeb程序,毫无疑问也是一样的HTTP请求/处理机制:
HTTP请求->Dispatch(配置文件web.xml定义路由映射)->获取request参数(SERVICE,VERSION,REQUEST,PARAMS)->构建service->构建operation->excute,获取result->返回Geoserver还有一些额外的东西
- spring 不想解释了,javaWeb的三辆马车之一。本质就是配置文件(applicationContext.xml)声明javaBean,交由Spring容器管理javaBean
- I18N(国际化) 通过配置文件xxx.properties 实现不同语言的国际化
- FreeMarker 模板+数据=输出
- GeoTools java类库满足OGC操作地理空间数据
-
Restful API Geoserver提供了大量的Restful风格的API供人调用。具体请查看官网
-
代码部署 将编译的war包,放到tomcat中即可运行Geoserver服务器
投影问题
EPSG:4326 即WGS84,是经纬度坐标 EPSG:3857 即球体(半径为WGS84的长半轴) + 墨卡托投影,俗称Web墨卡托投影 是平面坐标 (等价于谷歌的900913 以及 esri的102100)
爬虫
爬虫就是自动化采集互联网上的数据的程序。 爬虫已经成为了程序员所掌握的基本技能,同时也是进入高级开发不得不涉足的内容,为了一个爬虫程序,你需要在以下的领域有一定的了解:
- 学习任意的一门开发语言
- 学习网页前端脚本语言:html、css、js
- 了解HTTP协议、正则表达式、数据库和代理切换等知识
- 多线程并发抓取、任务调度、消息队列、分布式爬虫、图像识别、键鼠模拟、nosql数据库(高级爬虫)
- 浏览器内核实现(终极爬虫)
一个简单的爬虫
- Http请求(单爬虫或者多爬虫并发抓取) 其中不免要考虑验证问题,和抓取方式-是深度抓取还是广度抓取
- 数据解析(正则表达式),数据清洗(入库)
- 避免封杀 模拟浏览器、Cookie状态、连接数、代理IP
yacc/lex
研究自制编程语言的时候,稍稍看了点,并没有深入了解,后期在研究完编译原理之后,在回过来研究他们吧
- lex是一种扫描器,从输入序列中识别标记
- yacc定义了语法规范,对lex识别的标记进行某种操作
SpringBoot后台
和坤坤一起开发 地理信息平台 时使用的Java后台框架。整个项目由AngularJS+SpringBoot+MongoDB实现,前后端分离开发。
Vue前台+SpringBoot
搭建 可视化平台 ,因为AngularJS入门成本太高,选择了轻量级的前端框架Vue,结合SpringBoot,实现了一个较为简单的SPA。
SpringBoot重构
在借鉴网上的SpringBoot项目后,对自己的项目进行重构。
- 引入DTO(Data Transfer Object)
POJO往往是一个对象的全部展示,如果全部属性展示到前台,会过于复杂,我们没有必要将真个PO对象传递到客户端,因此引入DTO,对PO进行字段筛选。VO 这里要特别思考对象在表示层时的体现,因为目前项目是前后端分离的所以没有引入VO,但是在后端渲染时,是考虑引入VO的
- Annotation结合AOP 定义注解SysControl对API进行更细粒度的控制
- 分页查询
2018/07~2018/08 心心向往的“封闭”终于来了,一个月的时间,看看能做出个什么明堂。
模型封装
Fvocm和裂隙岩溶含水层地下水模型的封装,按部就班就完成了。
OpenLayer、Leflet、D3、ThreeJS
研究数据的可视化的时候,顺便回顾一下以前使用过的可视化JS库。
- OpenLayer和Leflet是地理空间数据的可视化,往往是二维的
- D3 是利用HTML、SVG、CSS实现数据的可视化
- ThreeJS 场景的可视化 由scene,camera,geometry,materail的OpenGL的体系
————————————————–;
2018/08~2018/10 感觉学习代码陷入了瓶颈,走入了弯路。
一方面是写了太多的业务代码,大多数都是处于CVM的状态,学到到是技巧,而不是技术。这些技巧就好比一个名字,告诉你你就知道了,网上一搜遍地都是(可怜的是,有些东西是你搜不到的,搜到了你也不会用的)。 另一方面是本来就不是专科出生,基础实在是太过于薄弱了,很多东西都是心有余而力不足。
如果是说要在编程的路上走下去的话,我还是希望能从头打好我的基础。因此:
编程基础是什么呢?就是那些年上过的却没有听过的课,离散数学、算法与数据结构、操作系统、计算机体系和网络结构、编译原理等课程。 哎,难受。还是那么一句老话,早知当初,何必如此。而且最难受的,研究生学习的课程也是泛泛而过的,莫不是到头来,也要重新学习一遍啊。
言归正传, 要对计算机本身,计算机网络,操作系统内核,系统平台,OO编程,程序的性能优化等有更深层次的掌握和认识。 我感觉要分为以下几个部分
- 扎实的计算机专业基础,包括算法和数据结构,操作系统,计算机网络,计算机体系结构和数据库等。
- 扎实的Java编程基础,IO以及多线程
- Linux常用指令和Shell脚本语言
- 精通多线程编程,熟悉分布式,缓存,消息队列等机制;熟悉JVM,包括内存模型、类加载机制以及性能优化
- 精通spring mvc、orm框架(ibatis或hibernate)、模板引擎(velocity)、关系型数据库设计及SQL、非结构数据库
- 面向对象编程、面向切面编程、函数式编程、设计模式
- 中间件
- SOA、Clouds等
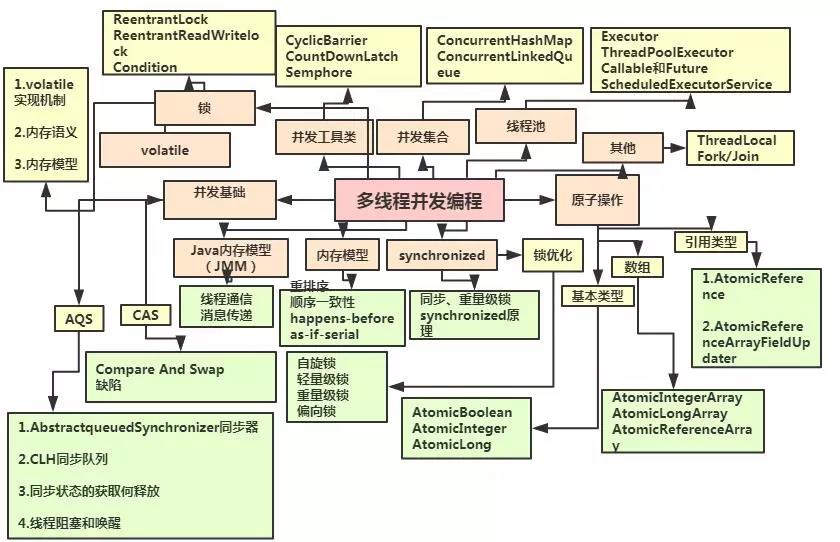
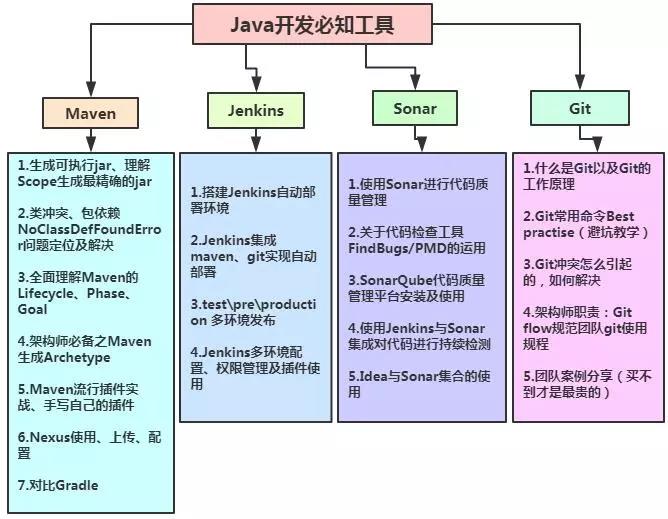
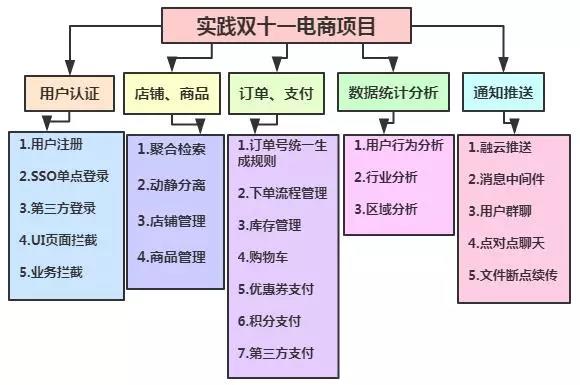
2018/10~2019/03 迷迷糊糊浑然不知道做了些什么
GraphQL
新的API的构建方式,由FaceBook就行主导。由于自身的技术栈是有Spring主导的,在项目中为了使用方便,我们可以添加以下的java类库:
<dependency>
<groupId>com.graphql-java-kickstart</groupId>
<artifactId>graphql-spring-boot-starter</artifactId>
<version>5.9.0</version>
</dependency>
<dependency>
<groupId>com.graphql-java-kickstart</groupId>
<artifactId>graphiql-spring-boot-starter</artifactId>
<version>5.9.0</version>
</dependency>
<dependency>
<groupId>com.graphql-java-kickstart</groupId>
<artifactId>graphql-java-tools</artifactId>
<version>5.6.1</version>
</dependency>
graphql-spring-boot-starter,涉及到graphql-java执行引擎,以及graphql-spring-boot-starter-webmvc完成了graphQL接入SpringBoot的功能。
graphiql-spring-boot-starter,提供了UI层直接访问GraphQL服务器的功能,类似Swagger与Swagger-UI的关系。
graphql-java-tools,更方便的在java环境中使用graphQL。在原生的graphql中,我们为了使用需要进行如下的步骤:
TypeDefinitionRegistry typeRegistry = new SchemaParser().parse(new File("schema.graphqls"));
//未能直接与type对应的字段 定义DataFeatcher
RuntimeWiring runtimeWiring = RuntimeWiring.newRuntimeWiring()
.type(newTypeWiring("Query")//Query定义DataFeatcher
.dataFetcher("bookById", graphQLDataFetchers.getBookByIdDataFetcher()))
.type(newTypeWiring("Book")//Book中的author字段需要额外的处理,无法直接使用默认PropertyDataFetcher
.dataFetcher("author", graphQLDataFetchers.getAuthorDataFetcher()))
.build();
GraphQLSchema graphQLSchema = new SchemaGenerator().makeExecutableSchema(typeRegistry, runtimeWiring);
GraphQL graphQL= GraphQL.newGraphQL(graphQLSchema).build();
而graphql-java-tools,为我们简化了其中的步骤
GraphQLSchema graphQLSchema = SchemaParser.newParser()
.file("schema.graphqls")
.resolvers(new Query(),new Mutation(),new EntityClassResolver())
.build()
.makeExecutableSchema();
其中的Query ,Mutation,EntityClassResolver实现了GraphQueryResolver\GraphMutationResolver\GraphQLResolver
恭喜毕业
:stuck_out_tongue_closed_eyes::stuck_out_tongue_closed_eyes::stuck_out_tongue_closed_eyes: