我是一个不甘落后的Java IT从业人员,我要紧跟时代的步伐。
1999 年,Sun 正式发布了 J2EE 的第一个版本。但从 1999 年诞生的第一个 J2EE 版本一直到 J2EE 1.4 版本,虽然它已经具有了强大的功能,但仍不太被人们接受。这是因为连实现一个简单的 J2EE 程序,都需要大量的配置文件,非常不便使用。在 2002 年,J2EE 1.4 推出后,复杂程度更是达到了顶点,尤其是 EJB 2.0,开发和调试的难度非常大。
2006 年 5 月份 Sun 正式发布了 J2EE 1.5(现改名为 Java EE 5)规范,Java EE 5 的主基调为“简化开发”。 即让开发者能够更方便、高效地使用 Java EE 技术。 从 Java EE 5 开始,通过引入注释、EJB 3.0 的业务组件、更新的 Web 服务和加强的持久化模型,将重心转移 提高开发人员的生产力 上来。
我们就将从Java 5 开始,一步步的看着Java是如何进行更新迭代的。
JAVA5 Generics
1.泛型
List<?> list2//通配符类型
List<? extends Number> list3//限制类型
2.可变参数
public static void test(String... values){
for (String value : values) {
System.out.println(value);
}
}
3.引入Annotations
@Retention (RetentionPolicy.RUNTIME)//指定运行时刻
@Target ({ ElementType.FIELD, ElementType.METHOD })//指定添加程序单元
public @interface MyAnnotation {
String value() default "";
}
4.引入迭代语句 1)遍历同时无法获取index 2)遍历同时无法删除元素
for (String value : values) {
System.out.println(value);
}
5.并发库
引 入ConcurrentHashMap与CopyOnWriteArrayList,在大并发量的时候引用
6.StringBuilder
链接两个字符串时调用
7.引入枚举类
Enum
8.自动装箱与拆箱
自动装箱就是Java自动将原始类型值转换成对应的对象,比如将int的变量转换成Integer对象,这个过程叫做装箱,反之将Integer对象转换成int类型值,这个过程叫做拆箱
| 类型 | ||||||||
|---|---|---|---|---|---|---|---|---|
| 原始类型 | byte | short | char | int | long | float | double | float |
| 封装类 | Byte | Short | Character | Integer | Long | Float | Double | Boolean |
具体的实现方式是:
//装箱
int i = 10;
Integer n = Integer.valueOf(i);
//拆箱
Integer n = Integer.valueOf(10);
int i=n.intValue();
注意一点,在Java 5中,在Integer的操作上引入了一个新功能来节省内存和提高性能。 整型对象通过使用相同的对象引用实现了缓存和重用。(适用范围是-128~127)
Integer a = 1000;
Integer b = 1000;
Integer c = 100;
Integer d = 100;
System.out.println("a == b is " + (a == b));//falsee
System.out.println(("c == d is " + (c == d)));//true
JAVA6
鸡肋的版本 1.Instrumentation 使用 Instrumentation,开发者可以构建一个独立于应用程序的代理程序(Agent),用来监测和协助运行在 JVM 上的程序,甚至能够替换和修改某些类的定义。有了这样的功能,开发者就可以实现更为灵活的运行时虚拟机监控和 Java 类操作了,这样的特性实际上提供了一种虚拟机级别支持的 AOP 实现方式,使得开发者无需对 JDK 做任何升级和改动,就可以实现某些 AOP 的功能了。
- HTTP 使得 Java SE 平台本身对网络编程,尤其是基于 HTTP 协议的因特网编程,有了更加强大的支持。
- NTLM认证
- 轻量级HTTP服务器
- Cookie管理
3.JMX 监控和管理JVM
4.编译器API
- 在运行时调用编译器,编译java文件 JavaCompiler
- 编译非文本形式的文件(内存中的字符串,或者从数据库中提取文件)JavaFileManager
5.Java DB 和 JDBC4.0
- 内嵌的Java数据库
- JDBC4.0 DriverManager 自动加载驱动
6.XML框架
- SAX框架(Simple API for XML) 使用事件处理机制来处理XML文件
- DOM框架(Document Object Model) 这个框架会建立一个对象模型。针对每个节点,以及节点之间的关系在内存中生成一个树形结构
- StAX 框架(Streaming API for XML) SAX 框架的缺点是不能记录正在处理元素的上下文。但是优点是运行时占内存空间比较小,效率高。DOM 框架由于在处理 XML 时需要为其构造一棵树,所以特点正好相反。StAX 框架出现于 Java SE 6 中,它的设计目标就是要结合 SAX 框架和 DOM 框架的优点。既要求运行时效率,也要求保持元素的上下文状态。
7.脚本引擎
java调用脚本
JAVA7
- 异常的suppress,捕获多异常
- switch 支持字符串
- 泛型自动判断类型
List<String> a=new ArrayList<>();
4.G1垃圾回收器
基于单线程标记扫描压缩算法(mark-sweep-compact),是以一种低延时的垃圾回收器来设计的,旨在避免进行 Full GC,但是当并发收集无法快速回收内存时,会触发垃圾回收器回退进行 Full GC。
- try-with-resources自动释放资源
不需要自动关闭流
try (BufferedReader reader = new BufferedReader(new FileReader(path))) {
StringBuilder builder = new StringBuilder();
String line = null;
while ((line = reader.readLine()) != null) {
builder.append(line);
builder.append(String.format("%n"));
}
return builder.toString();
}
6.path
关于路径的接口,避免自己进行路径字符串拼接。 用Path对象来实现对文件或者文件夹进行操作。Path代表文件在文件系统中的位置。
- java.nio.file.Paths 包含了用于创建Path对象的静态方法
- java.nio.file.Path 包含了大量用于操纵文件路径的方法
- java.nio.file.FileSystems 用于访问文件系统的类
- java.nio.file.FileSystem 代表了一种文件系统,例如Unix下的根目录为 / ,而Windows下则为C盘
一旦获取了某个路径的Path对象,我们就能获取文件系统中的各种信息,以及如何操作该path。
Path path= FileSystems.getDefault().getPath("F://test.txt");
Path pathFromFile=new File("F://test.txt").toPath();
Path dir=Paths.get("F:/");
dir.resolve("test.txt");// c:/test.txt 追加
dir.resolveSibling("test1.txt") // c:/test1.txt 替换最后的路径
dir.relativize(path); //test.txt 返回dir到path的路径
由此我们可以忘记java.io.File的操作。
7.NIO(New I/O)
- 目录操作
public static void listFiles() throws IOException {
Path path = Paths.get("");
try (DirectoryStream<Path> stream = Files.newDirectoryStream(path, "*.*")) {
for (Path entry: stream) {
//使用entry
System.out.println(entry);
}
}
}
Path directoryPath = Paths.get("D:/home/sample");
Files.createDirectory(directoryPath);
- Files 文件操作
Path path = FileSystems.getDefault().getPath("F:\\test.txt");
Files.createFile(Path);
Files.copy(src,target,StandardCopyOption.REPLACE_EXISTING);
Files.delete(sourceFile);
//读取文件的详细信息
BasicFileAttributes attributes = Files.readAttributes(path,BasicFileAttributes.class);
8.Bean Validation的广泛运用
9.Java API for WebSocket1.0
基于 HTTP 的 WebSockets 为解决低延迟和双向通信提供了一种解决方案。在 WebSocket API 的最基层是一个带注释的 Java 对象(POJO)
@ServerEndpoint("/test")
public class TestEndpoint{
@OnOpen
public void onOpen(...){ }
@OnClose
public void onClose(...){ }
@OnError
public void onError(...){ }
@OnMessage
public void testMessage(String message,...){ }
}
通过注释@ServerEndpoint来指定一个URL,WebSocket API 的最基层支持发送和接收简单文本和二进制信息;WebSocket 利用现有 Web 容器的安全特性,开发人员只需付出较少的代价就可以建立良好的保密通信。
10.Servlet3.1
在 Java EE 6,Servlet 异步 I/O 通过移除“一个请求需要一个线程”的限制,使一个线程可以处理多个并发请求。这可以使 HTML5 客户端快速得到响应。但是,如果服务器端读取数据的速度比客户端发送的速度要快,那么可能会由于缓慢的客户端连接而不能提供更多的数据导致线程阻塞,这样就限制了扩展性。在 Java EE 7 中使用新的事件驱动 API Servlet 3.1 从客户端读取数据将不会造成阻塞。如果有数据可用时,Servlet 线程将会读取和处理这些数据,否则就去处理其他请求。
11.更多带注释的POJO
通过注释 Java EE 使开发人员更专注于 Java 对象的编程而无需关注繁琐的配置。开发人员可以不需要任何配置而是简单的使用 @Inject 来注入任何 Java 对象。
12.常量池被放到堆空间中
1.6 之前的版本,常量池被放置到Perm区(方法区)中,
13.Switch 支持String类型
由此Switch支持char, byte, short, int, Character, Byte, Short, Integer, String, or an enum`,但是在其编译后都是将其转化为了整型进行比较。
注意Switch不支持long。
Incompatible types. Found: 'long', required: 'char, byte, short, int, Character, Byte, Short, Integer, String, or an enum'
JAVA8
- 函数式接口/SAM接口(Single Abstract Method Interfaces)
在介绍函数式接口之前,我们先来讨论编程。
面向过程编程
面向过程的程序设计把计算机程序视为一系列的命令集合,即一组函数的顺序执行。为了简化程序设计,面向过程把函数继续切分为子函数,即把大块函数通过切割成小块函数来降低系统的复杂度。
自定而下,把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。
函数就是面向过程的程序设计的基本单元。
面向对象编程
面向对象的程序设计把计算机程序视为一组对象的集合,而每个对象都可以接收其他对象发过来的消息,并处理这些消息,计算机程序的执行就是一系列消息在各个对象之间传递。
它允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。
类就是面向对象的程序设计的基本单元。将程序和数据封装其中,以提高软件的重用性、灵活性和扩展性,对象里的程序可以访问及经常修改对象相关连的数据。
函数式编程
JavaScript就是函数式编程的典范。
函数式编程就是一种抽象程度很高的编程范式,它将电脑运算视为数学上的函数计算,将计算过程分解成了多个可服用的函数,并且避免使用程序状态以及易变对象。(在一定程度上,函数式编程是面向过程编程的一种,但其思想更接近于数学计算)
纯粹的函数式编程语言编写的函数没有变量,因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用。
函数式编程的十分容易并行,因为我在运行时不会修改状态,因此无论多少线程在运行时都可以观察到正确的状态,没有并发编程的问题,是线程安全的。
两个函数完全无关,因此它们是并行还是顺序地执行便没有什么区别了。函数式编程可以更好的并发处理,甚至可以微码化,而过程、对象方式则属于串行(或轮询)处理。
函数式编程的表达方式更加符合人类日常生活中的语法,代码可读性更强。
实现同样的功能函数式编程所需要的代码比面向对象编程要少很多,代码更加简洁明晰。
特点:
- 函数是一等公民,指的是函数与其他数据类型一样,处于平等地位,可以赋值给其他变量,也可以作为参数,传入另一个函数,或者作为别的函数的返回值。
- 闭包,
定义在一个函数内部的函数 - 高阶函数,高阶函数可以用另一个函数(间接地,用一个表达式) 作为其输入参数,在某些情况下,它甚至返回一个函数作为其输出参数。这两种结构结合在一起使得可以用优雅的方式进行模块化编程,这是使用 函数式编程 的最大好处。
- 惰性求值(Lazy Evaluation):抵消相同项从而避免执行无谓的代码,安排代码执行顺序从而实现更高的执行效率甚至是减少错误。
- 没有副作用(Side effect):指的是函数内部与外部互动(最典型的情况,就是修改全局变量的值),产生运算以外的其他结果。函数式编程强调没有”副作用”,意味着函数要保持独立,所有功能就是返回一个新的值,没有其他行为,尤其是不得修改外部变量的值。
响应式编程
传统的编程方式,是顺序执行的,上一个任务没有完成的话需要等待直至完成之后才会执行下一个任务。无论是提升机器的性能还是代码的性能,本质上都需要依赖上一个任务的完成。如果需要响应迅速,就得把同步执行的方式换成异步,方法执行变成消息发送。这变成了异步编程的方式,它是响应式编程的重要特性之一。
响应式编程是依赖于时间的,响应式代码的运行不是按照代码的顺序,而是根据按时间发生的事件有关。
依赖于事件?这不就是回调吗?但在响应式编程里面,这些按时间排列的时间,被称为Stream
在这种思维中所有的东西都是流,你可以对这些流的各种操作,合并流,过滤流,一个流input另一个流等等,没有流,就没有响应式编程。
特点:
- 异步编程:提供了合适的异步编程模型,能够挖掘多核CPU的能力、提高效率、降低延迟和阻塞等。
- 数据流:基于数据流模型,响应式编程提供一套统一的Stream风格的数据处理接口。和Java 8中的Stream相比,响应式编程除了支持静态数据流,还支持动态数据流,并且允许复用和同时接入多个订阅者。
- 变化传播:简单来说就是以一个数据流为输入,经过一连串操作转化为另一个数据流,然后分发给各个订阅者的过程。这就有点像函数式编程中的组合函数,将多个函数串联起来,把一组输入数据转化为格式迥异的输出数据。
总结: 传统的面向对象编程通过抽象出的对象关系来解决问题。 函数式编程通过function的组合来解决问题。 响应式编程通过函数式编程的方式来解决回调地狱的问题。
Java是面向对象的语言,除了原始数据类型之外,Java的所有内容都是一个对象。而在函数式编程中,我们只需要面向函数,给函数分配变量,并将这个函数作为参数再传递给别的函数即可实现特定的功能。
Lambda 表达式的加入,使得 Java 拥有了函数式编程的能力。
在其它语言中,Lambda 表达式的类型是一个函数;但在 Java 中,Lambda 表达式被表示为对象,因此它们必须绑定到被称为功能接口的特定对象类型。
功能接口
@FunctionalInterface ,本质上也是一种接口,但他是一种特殊的接口:单抽象方法的接口。
- 函数式接口内部可以包含默认方法 default
- 函数式接口内部可以包含静态方法 static
- 函数式接口内部只能包含一个抽象方法 static
对于普通接口,我们使用时需要定义一个类来实现其中的方法。而函数式接口除了使用普通的匿名类方法来实现以外,还支持lambda表达式来实现。
因此当我们使用这种接口,作为函数的参数的时候,我们就可以传入一个Lambda表达式作为参数,执行的时候就会自动执行函数式接口中的唯一方法。
//定义
@FunctionalInterface
public interface Check<T> {
public abstract boolean checkString(T t);
}
//声明以及使用
Check check=new Check() {
@Override
public boolean checkString(Object o) {
System.out.println(o);
return o.getClass().equals(String.class);
}
};
Check checkLambda=(s)->{
System.out.println(s);
return s.getClass().equals(String.class);
};
check.checkString(1);//false
check.checkString("sunlingzhi")//true
要使用Lambda表达式就需要定义一个函数式接口,这样往往会让程序充斥过量的仅为Lambda表达式服务的函数式接口。为了减少这些过量的接口, JAVA8 增加了一些函数式通用接口,如:
- Function<T,R>: T为输入,R为输出 apply(T t):R
- Predicate<T>: T为输入,返回布尔值 test(T t):boolean
- Consumer<T>: T为输入,无返回值 accept(T t):void
- Comparator<T,T> 比较T T 返回true|false
- Supplier<T> 无输入,“生产”一个T类型的返回值。 get():T
- Lambda 表达式(重磅)
Lambda表达式就是一个匿名函数,可以作为函数式编程的输入、输出 在没有Lambda时,代码是这样的:
public int add(int x,int y){
return x + y;
}
在使用lambda后是这样的:
(int x,int y) -> x + y;
(x,y)->x+y;
(x,y)->{return x+y;}
通过Lambda表达式使代码可读性增加,并且更加简洁
Lambda表达式无法操作外部变量,因为Lambda实质上是接口的子对象,只能访问静态资源和本身的内部变量
为何需要Lamba
在Java之前,我们想要将某些功能,方法传递给某些方法,我们需要去写匿名类。
manager.addScheduleListener(new ScheduleListener() {
@Override
public void onSchedule(ScheduleEvent e) {
// Event listener implementation goes here...
}
});
我们通过匿名内部类(局部内部类),将一些功能传递到onSchedule方法中。
注意局部内部类的使用情况
正是 Java 在作为参数传递普通方法或功能的限制,Java 8 增加了一个全新语言级别的功能,称为 Lambda 表达式。 Java 是面向对象语言,除了原始数据类型之处,Java 中的所有内容都是一个对象。而在函数式语言中,我们只需要给函数分配变量,并将这个函数作为参数传递给其它函数就可实现特定的功能。
Lambda 表达式的加入,使得 Java 拥有了函数式编程的能力。在其它语言中,Lambda 表达式的类型是一个函数;但在 Java 中,Lambda 表达式被表示为对象,因此它们必须绑定到被称为功能接口的特定对象类型。
具体体现
Lambda表达式的表达形式是 一个匿名函数 。 简单来说,这是一个没有声明的方法,即没有访问修饰符,没有返回值声明和名称。 在仅用一次方法的地方特别有用,为我们们节省了,如包含类声明和编写单独方法的工作。
List.forEach()实例
注意 forEach 是无法 跳出的 ,所有的操作都有进行。
forEach方法,对List集合中的每一个元素都实现了Consumer
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7);
list.forEach(el->{
System.out.println(el);
});
list.forEach(el-> System.out.println(el));
list.forEach(System.out::println);
Lambda和匿名类的区别
- 1.this关键字。 对于匿名类this关键字是匿名类本身,而Lambda表达式,解析为写入lambda的类。
- 2.解析方式 对于匿名类,会编译为两个class文件,如out.class与outer$inner.class; 对于Lambda,会将其转化为类的私有方法,再进行编译。
3.方法引用
当Lambda表达式里面只执行已知的方法时,可以用方法引用来写出简洁的代码.
Checker checker2=String::isEmpty;
静态方法引用:ClassName::methodName 实例上的实例方法引用:instanceReference::methodName 超类上的实例方法引用:super::methodName 类型上的实例方法引用:ClassName::methodName 构造方法引用:Class::new 数组构造方法引用:TypeName[]::new
4.集合的stream操作
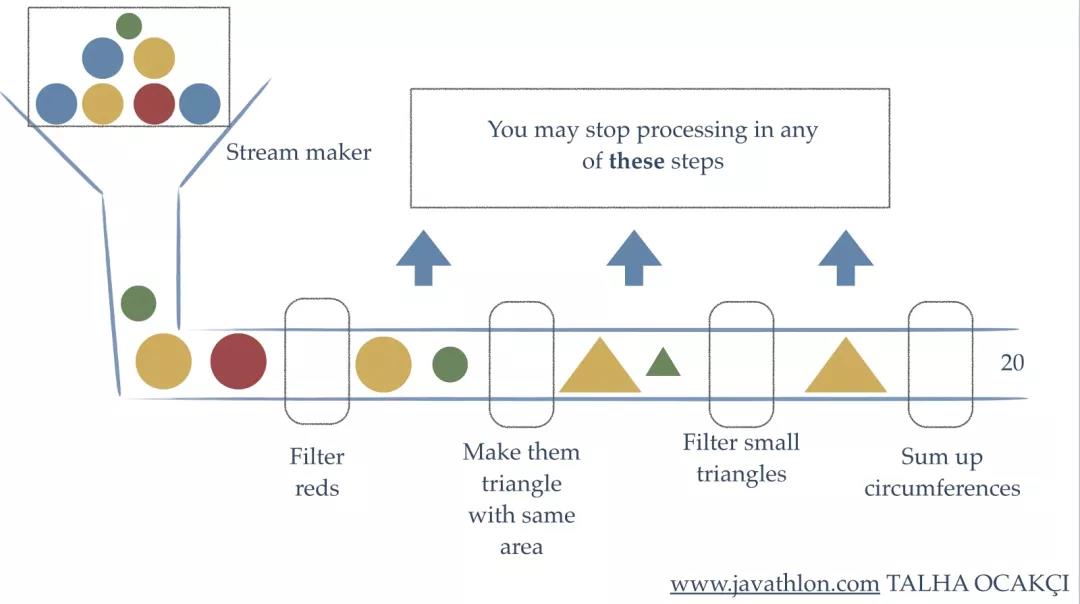
对流而言,主要有三种关键性操作:分别是创建、中间操作以及最终操作。
Java 8 引入了流式操作(Stream),通过该操作可以实现对集合(Collection)的并行处理和函数式操作。当然我们也可以通过Stream直接创建流
Stream<String> stream = Stream.of("Hollis", "HollisChuang", "hollis", "Hello", "HelloWorld", "Hollis");
中间操作都必须是Functional iterface ,常见的中间操作包括
- filter:Filter items according to a given predicate
- map:Process items and transform
- limit :Limit the results
- skip: 扔掉
- sorted :排序
- distinct:去重
- subStream 获取子Stream
- reduce
- collect
- peek
- average
- sum
- max
- min
Stream经过中间操作之后还是一个Stream,我们必须将Stream转换为我们需要的类型,这就需要最终操作,最终操作会消耗流,且流不可再次使用。
终止操作:
- forEach
- collect 对流进行归约操作,可以接受各种做法作为参数,将流中的元素累积成一个汇总结果
- findFirst
- count
- anyMatch
根据操作返回的结果不同,流式操作分为中间操作和最终操作两种。最终操作返回一特定类型的结果,而中间操作返回流本身,这样就可以将多个操作依次串联起来。 根据流的并发性,流又可以分为串行和并行两种。流式操作实现了集合的过滤、排序、映射等功能。
流有串行和并行两种,串行流上的操作是在一个线程中依次完成,而并行流则是在多个线程上同时执行。并行与串行的流可以相互切换:通过 stream.sequential() 返回串行的流,通过 stream.parallel() 返回并行的流。相比较串行的流,并行的流可以很大程度上提高程序的执行效率。 下面是分别用串行和并行的方式对集合进行排序。
串行排序:
List<String> list = new ArrayList<String>();
for(int i=0;i<1000000;i++){
double d = Math.random()*1000;
list.add(d);
}
//下面是流的排序 快 不会改变list
list.stream().sequential().sorted();
list.stream().parallel().sorted();
//下面这种是集合的排序 稍微慢点 会改变list
list.sort(Comparator.compration(Double::doubleValue))
list.sort((h1, h2) -> {
return h1.compareTo(h2);
});
5.提高HashMap
输入域通过哈希函数得到一个输出域,把输出域对M进行取余之后得到一个长度为M的数组,这个数组的每个位置都叫做 一个位桶,每个位桶都是几乎均匀分布的,我们用链表来当做每个位桶的数据结构。 当位链表的长度大于8时,我们采用红黑树来代替链表这种数据结构。
- 日期管理
//LocalDate
LocalDate localDate = LocalDate.now(); //获取本地日期
localDate = LocalDate.ofYearDay(2014, 200); // 获得 2014 年的第 200 天
System.out.println(localDate.toString());//输出:2014-07-19
localDate = LocalDate.of(2014, Month.SEPTEMBER, 10); //2014 年 9 月 10 日
System.out.println(localDate.toString());//输出:2014-09-10
//LocalTime
LocalTime localTime = LocalTime.now(); //获取当前时间
System.out.println(localTime.toString());//输出当前时间
localTime = LocalTime.of(10, 20, 50);//获得 10:20:50 的时间点
System.out.println(localTime.toString());//输出: 10:20:50
//Clock 时钟
Clock clock = Clock.systemDefaultZone();//获取系统默认时区 (当前瞬时时间 )
long millis = clock.millis();//
- IO/NIO的改进
增加了一些新的 IO/NIO 方法,使用这些方法可以从文件或者输入流中获取流(java.util.stream.Stream),通过对流的操作,可以简化文本行处理、目录遍历和文件查找。
新增的API如下:
BufferedReader.line(): 返回文本行的流 Stream<String>
File.lines(Path, Charset):返回文本行的流 Stream<String>
File.list(Path): 遍历当前目录下的文件和目录
File.walk(Path, int, FileVisitOption): 遍历某一个目录下的所有文件和指定深度的子目录
File.find(Path, int, BiPredicate, FileVisitOption… ): 查找相应的文件
-
Optional
-
接口内部可以定义static方法、default方法
接口越来越与抽象类的功能类似了,你可以在接口内部写具体实现。
static方法, 可以直接使用 接口名.static方法名调用
default 方法(可以不用在实现类中实现), 需要构建对象 接口名 a=new 实现接口类 + a.default方法
接口default方法的重要性:添加新方法而不需要原本已经存在的实现该接口的类做任何改变(甚至不需要重新编译)就可以使用该新版本的接口。
10.扩展了注解的使用范围 Java8之后,几乎可以为任何东西添加注解
同时可以添加重复注解
ElementType.TYPE
FIELD
METHOD
PARAMETER
CONSTRUCTOR
LOCAL_VARIABLE
ANNOTATION_TYPE
PACKAGE
TYPE_PARAMETER
TYPE_USE
MODULE
JAVA9(跳票)
- 模块化系统
- HTTP2.0
- Process API
增加ProcessHandle接口,适合于管理长时间运行的进程。
在使用 ProcessBuilder 来启动一个进程之后,可以通过 Process.toHandle()方法来得到一个 ProcessHandle 对象的实例。通过 ProcessHandle 可以获取到ProcessHandle.Info。ProcessHandle 的 onExit()方法返回一个 CompletableFuture<ProcessHandle>对象,可以在进程结束时执行自定义的动作。
final ProcessBuilder processBuilder = new ProcessBuilder("top")
.inheritIO();
final ProcessHandle processHandle = processBuilder.start().toHandle();
processHandle.onExit().whenCompleteAsync((handle, throwable) -> {
if (throwable == null) {
System.out.println(handle.pid());
} else {
throwable.printStackTrace();
}
});
4.Stack-Waling APO
5.使用G1作为默认的垃圾收集器,替换了原来的Parallel GC
代码上的增加
6.集合
在集合上创建不可变集合,该集合不可修改
List.of(1, 2, 3);
Set.of(1, 2, 3);
Map.of("Hello", 1, "World", 2);
7.接口可以定义私有方法
JAVA10
- 局部变量的类型推断
你可以随意定义变量而不必指定变量的类型
简化和改善了开发者的体验,允许开发人员省略通常不必要的局部变量类型初始化声明。
当然局部变量类型推断受限于以下场景:
- 局部变量初始化
- for循环内部索引变量
var list=new ArrayList<>();//这里类型推断,list可以add任何类型的对象Object
2.垃圾回收
-
垃圾收集器接口。通过引入一个干净的垃圾收集器(GC)接口,改善不同垃圾收集器的源码隔离性。
-
向G1引入并行Full GC,以改善G1最坏情况的等待时间。
将为 G1 引入多线程并行 GC(并行化 mark-sweep-compact 算法),同时会使用与年轻代回收和混合回收相同的并行工作线程数量,从而减少了 Full GC 的发生,以带来更好的性能提升、更大的吞吐量。
3.线程局部管控 线程局部管控。允许停止单个线程,而不是只能启用或停止所有线程