同步、异步、阻塞、非阻塞
同步:是一个任务的完成需要依赖另一个任务,只有等被依赖的任务完成后,依赖的任务才能完成。 异步:只需要通知被依赖的任务要完成任务,依赖的任务也立即执行。至于被依赖的任务最终是否真正完成,依赖它的任务无法确定,所以它是不可靠的任务序列。
同步就是 主线程中依此执行。 异步可以由 在主线程中开辟新的线程去执行任务 实现。
阻塞:CPU等到IO读取 非阻塞:CPU去干别的事,等IO读取完成,CPU接着做后续的事情。
| 组合 | 地址 |
|---|---|
| 同步阻塞 | 最常用的一种用法,使用也是最简单的,但是 I/O 性能一般很差,CPU 大部分在空闲状态。 |
| 同步非阻塞 | 提升 I/O 性能的常用手段,就是将 I/O 的阻塞改成非阻塞方式,尤其在网络 I/O 是长连接,同时传输数据也不是很多的情况下,提升性能非常有效。 这种方式通常能提升 I/O 性能,但是会增加CPU 消耗,要考虑增加的 I/O 性能能不能补偿 CPU 的消耗,也就是系统的瓶颈是在 I/O 还是在 CPU 上。 |
| 异步阻塞 | 这种方式在分布式数据库中经常用到,例如在网一个分布式数据库中写一条记录,通常会有一份是同步阻塞的记录,而还有两至三份是备份记录会写到其它机器上,这些备份记录通常都是采用异步阻塞的方式写 I/O。异步阻塞对网络 I/O 能够提升效率,尤其像上面这种同时写多份相同数据的情况。 |
| 异步非阻塞 | 这种组合方式用起来比较复杂,只有在一些非常复杂的分布式情况下使用,像集群之间的消息同步机制一般用这种 I/O 组合方式。如 Cassandra 的 Gossip 通信机制就是采用异步非阻塞的方式。它适合同时要传多份相同的数据到集群中不同的机器,同时数据的传输量虽然不大,但是却非常频繁。这种网络 I/O 用这个方式性能能达到最高。 |
IO
在计算机系统中I/O就是输入(Input)和输出(Output)的意思,针对不同的操作对象,可以划分为:
- 磁盘I/O模型
- 网络I/O模型,Socket
- 内存映射I/O,Serializable
- Direct I/O
- 数据库I/O
只要具有输入输出类型的交互系统都可以认为是I/O系统,也可以说I/O是整个操作系统数据交换与人机交互的通道,这个概念与选用的开发语言没有关系,是一个通用的概念。
在如今的系统中I/O却拥有很重要的位置,现在系统都有可能处理大量文件,大量数据库操作,而这些操作都依赖于系统的I/O性能,也就造成了现在系统的瓶颈往往都是由于I/O性能造成的。因此,为了解决磁盘I/O性能慢的问题,系统架构中添加了缓存来提高响应速度;或者有些高端服务器从硬件级入手,使用了固态硬盘(SSD)来替换传统机械硬盘;在大数据方面,Spark越来越多的承担了实时性计算任务,而传统的Hadoop体系则大多应用在了离线计算与大量数据存储的场景,这也是由于磁盘I/O性能远不如内存I/O性能而造成的格局(Spark更多的使用了内存,而MapReduece更多的使用了磁盘)。因此,一个系统的优化空间,往往都在低效率的I/O环节上,很少看到一个系统CPU、内存的性能是其整个系统的瓶颈。
BIO
BIO (Blocking I/O):同步阻塞I/O,数据的读取写入必须阻塞在一个线程内等待其完成。
这是最基本与简单的I/O操作方式,其根本特性是做完一件事再去做另一件事,一件事一定要等前一件事做完,这很符合程序员传统的顺序来开发思想,因此BIO模型程序开发起来较为简单,易于把握。
当用read去读取网络的数据时,是无法预知对方是否已经发送数据的。因此在收到数据之前,能做的只有等待,直到对方把数据发过来,或者等到网络超时。
于是,网络服务为了同时响应多个并发的网络请求,必须实现为多线程的。每个线程处理一个网络请求。线程数随着并发连接数线性增长。那么CPU的执行时机都会浪费在线程的切换中,使得线程的执行效率大大降低。
问题的关键在于,当调用read接受网络请求时,有数据到了就用,没数据到时,实际上是可以干别的。使用大量线程,仅仅是因为Block发生,没有其他办法。
NIO
NIO (Non-blockin I/O):同步非阻塞I/O,NIO本身是基于事件驱动的思想来实现的, 其目的就是解决BIO的大并发问题,在BIO模型中,如果需要并发处理多个I/O请求,那就需要多线程来支持. NIO使用了多路复用器机制,以socket使用来说,多路复用器通过不断轮询各个连接的状态,只有在socket有流可读或者可写时,应用程序才需要去处理它,在线程的使用上,就不需要一个连接就必须使用一个处理线程了,而是只是有效请求时(确实需要进行I/O处理时),才会使用一个线程去处理,这样就避免了BIO模型下大量线程处于阻塞等待状态的情景。
Java NIO
Java NIO提供了与标准IO不同的IO工作方式,传统的IO基于字节流和字符流进行操作,意味着从一个流中读取若干个字节,直至读取所有的字节,他们没被缓存到任何地方,此外他不可以对流进行前后移动。因为前后移动,你就需要一个缓冲区将当前流给缓存给一个缓冲区。
而NIO基于Channels and Buffers(通道和缓冲区),数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中,有了缓冲区就能够前后移动,提高了处理过程的灵活性;同时可以利用Selector用于监听多个通道的事件(比如连接打开,数据抵达),由此,单个线程可以通过监听多个数据通道。
案列:
RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
FileChannel inChannel = aFile.getChannel();
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buf);
while (bytesRead != -1) {
System.out.println("Read " + bytesRead);
buf.flip();
while(buf.hasRemaining()){
System.out.print((char) buf.get());
}
buf.clear();
bytesRead = inChannel.read(buf);
}
aFile.close();
Channel
Channel是通道,是一种双向的通道,既可以读也可以写;而传统的stream是单向的,比如InputStream, OutputStream。
- FileChannel 从文件中读写数据。
- DatagramChannel 能通过UDP读写网络中的数据。
- SocketChannel 能通过TCP读写网络中的数据。
- ServerSocketChannel 以监听新进来的TCP连接,像Web服务器那样。对每一个新进来的连接都会创建一个SocketChannel。
Buffer
ByteBuffer, CharBuffer, DoubleBuffer, FloatBuffer, IntBuffer, LongBuffer, ShortBuffer,
MappedByteBuffer
利用虚拟内存,处理大文件
HeapByteBuffer
其内存直接分配在堆上,减少了内存拷贝操作
DirectByteBuffer
系统就可以直接从内存将数据写入到 Channel 中,而无需进行 Java 堆的内存申请,复制等操作,提高了性能。但是DirectByteBuffer 是通过full gc来回收内存的,DirectByteBuffer会自己检测情况而调用 system.gc(),但是如果参数中使用了 DisableExplicitGC 那么就无法回收该快内存了,-XX:+DisableExplicitGC标志自动将 System.gc() 调用转换成一个空操作,就是应用中调用 System.gc() 会变成一个空操作,那么如果设置了就需要我们手动来回收内存了,所以DirectByteBuffer使用起来相对于完全托管于 java 内存管理的Heap ByteBuffer 来说更复杂一些,如果用不好可能会引起OOM。Direct ByteBuffer 的内存大小受 -XX:MaxDirectMemorySize JVM 参数控制(默认大小64M),在 DirectByteBuffer 申请内存空间达到该设置大小后,会触发 Full GC。
Selector
Selector是NIO相对于BIO实现多路复用的基础,Selector运行单线程处理多个Channel, 要使用Selector,必须向Selector注册Channel,然后调用它的select方法,这个方法会一直阻塞到某个注册的channel的通道有事件就绪。一旦这个方法返回,线程就可以处理这些事件,事件的例子有如新的连接进来、数据接收等。
AIO
AIO ( Asynchronous I/O):异步非阻塞I/O模型。
Java AIO就是Java作为对异步IO提供支持的NIO.2 ,Java NIO2 (JSR 203)定义了更多的 New I/O APIs, 提案2003提出,直到2011年才发布, 最终在JDK 7中才实现。JSR 203除了提供更多的文件系统操作API(包括可插拔的自定义的文件系统), 还提供了对socket和文件的异步 I/O操作。 同时实现了JSR-51提案中的socket channel全部功能,包括对绑定, option配置的支持以及多播multicast的实现。
从编程模式上来看AIO相对于NIO的区别在于,NIO需要使用者线程不停的轮询IO对象,来确定是否有数据准备好可以读了,而AIO则是在数据准备好之后,才会通知数据使用者,这样使用者就不需要不停地轮询了。当然AIO的异步特性并不是Java实现的伪异步,而是使用了系统底层API的支持,在Unix系统下,采用了epoll IO模型,而windows便是使用了IOCP模型。关于Java AIO,本篇只做一个抛砖引玉的介绍,如果你在实际工作中用到了,那么可以参考Netty在高并发下使用AIO的相关技术。
总结
IO实质上与线程没有太多的关系,但是不同的IO模型改变了应用程序使用线程的方式,NIO与AIO的出现解决了很多BIO无法解决的并发问题,当然任何技术抛开适用场景都是耍流氓,复杂的技术往往是为了解决简单技术无法解决的问题而设计的,在系统开发中能用常规技术解决的问题,绝不用复杂技术,否则大大增加系统代码的维护难度,学习IT技术不是为了炫技,而是要实实在在解决问题。
JAVA I/O
磁盘操作
File可以用于表示文件和目录的信息,但是它不表示文件的内容。
从Java7以后,我们可以用java.nio提供的Paths和Files来代替File,以区分文件和目录。
字节操作(装饰者模式)
字节操作既是流的操作:
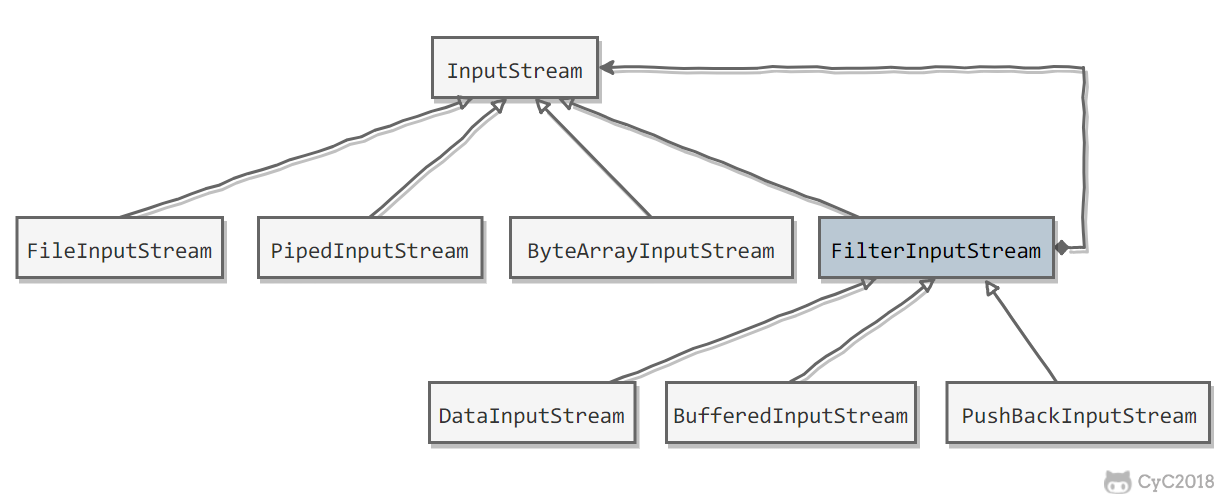
- InputStream 是抽象组件
- FileInputStream 是 InputStream 的子类,属于具体组件,提供了字节流的输入操作
- PipeInputStream
- ByteArrayInputStream
- FileterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。
- DataInputStream 提供了对更多数据类型进行输入的操作,比如 int、double 等基本类型
- PushBackInpustStream 提供了回退的功能。
- BufferedInputStream 为 InputStream 提供缓存的功能。
实例化一个具有缓存功能的字节流对象,我们只需要在FileInputStream对象上嵌套一层BufferedInputStream:
FileInputStream fileInputStream = new FileInputStream(filePath); BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
- OutputStream
- FileOutputStream
字符操作
编码和解码
编码就是把字符变成字节,解码就是把字节重新组合成字符。
如果编码和解码过程使用不同的编码方式那么就出现了乱码。
- GBK 编码中,中文字符占 2 个字节,英文字符占 1 个字节;
- UTF-8 编码中,中文字符占 3 个字节,英文字符占 1 个字节;
- UTF-16be(Big Endian) 编码中,中文字符和英文字符都占 2 个字节。
- UTF-16le(Little Endian) 编码中,中文字符和英文字符都占 2 个字节。
Java 的内存编码使用双字节编码 UTF-16be,这不是指 Java 只支持这一种编码方式,而是说 char 这种类型使用 UTF-16be 进行编码。char 类型占 16 位,也就是两个字节,Java 使用这种双字节编码是为了让一个中文或者一个英文都能使用一个 char 来存储。
String的编码
在java1.8中 String的值是有 char[] value存储,在java1.9中是由byte[] value和byte coder存储,增加了编码的存在。
在调用无参数 getBytes() 方法时,默认的编码方式不是 UTF-16be。双字节编码的好处是可以使用一个 char 存储中文和英文,而将 String 转为 bytes[] 字节数组就不再需要这个好处,因此也就不再需要双字节编码。getBytes() 的默认编码方式与平台有关,一般为 UTF-8。
byte[] bytes = str1.getBytes();
Reader 与 Writer
不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符。但是在程序中操作的通常是字符形式的数据,因此需要提供对字符进行操作的方法。
- InputStreamReader 实现从字节流解码成字符流;
- OutputStreamWriter 实现字符流编码成为字节流。
public static void readFileContent(String filePath) throws IOException {
FileReader fileReader = new FileReader(filePath);
BufferedReader bufferedReader = new BufferedReader(fileReader);//装饰者模式
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
// 装饰者模式使得 BufferedReader 组合了一个 Reader 对象
// 在调用 BufferedReader 的 close() 方法时会去调用 Reader 的 close() 方法
// 因此只要一个 close() 调用即可
bufferedReader.close();
}
对象操作
序列化和反序列化
序列化就是将一个对象转换成字节序列,方便存储和传输。
- 序列化:ObjectOutputStream.writeObject()
- 反序列化:ObjectInputStream.readObject()
不会对静态变量进行序列化,因为序列化只是保存对象的状态,静态变量属于类的状态。
Serializable
序列化的类需要实现 Serializable 接口,它只是一个标准,没有任何方法需要实现,但是如果不去实现它的话而进行序列化,会抛出异常。
transient
transient 关键字可以使一些属性不会被序列化。
ArrayList 中存储数据的数组 elementData 是用 transient 修饰的,因为这个数组是动态扩展的,并不是所有的空间都被使用,因此就不需要所有的内容都被序列化。通过重写序列化和反序列化方法,使得可以只序列化数组中有内容的那部分数据
private transient Object[] elementData;
网络操作
- InetAddress:用于表示网络上的硬件资源,即 IP 地址;
- URL:统一资源定位符;
- Sockets:使用 TCP 协议实现网络通信;
- Datagram:使用 UDP 协议实现网络通信。
Netty
那么Netty到底是何方神圣? 用一句简单的话来说就是:Netty封装了JDK的NIO,让你用得更爽,你不用再写一大堆复杂的代码了。 用官方正式的话来说就是:Netty是一个异步事件驱动的网络应用框架,用于快速开发可维护的高性能服务器和客户端。
- 使用JDK自带的NIO需要了解太多的概念,编程复杂,一不小心bug横飞
- Netty底层IO模型随意切换,而这一切只需要做微小的改动,改改参数,Netty可以直接从NIO模型变身为IO模型
- Netty自带的拆包解包,异常检测等机制让你从NIO的繁重细节中脱离出来,让你只需要关心业务逻辑
- Netty解决了JDK的很多包括空轮询在内的bug
- Netty底层对线程,selector做了很多细小的优化,精心设计的reactor线程模型做到非常高效的并发处理
- 自带各种协议栈让你处理任何一种通用协议都几乎不用亲自动手
- Netty社区活跃,遇到问题随时邮件列表或者issue
- Netty已经历各大rpc框架,消息中间件,分布式通信中间件线上的广泛验证,健壮性无比强大