接口风格设计
屁股决定脑袋,所以如何统一的设计项目的接口风格,完全取决于你的项目情况。
RPC
Remote Procedure Call(远程过程调用),它是面向过程的。
遵循RPC协议设计的接口,是基于网络采用C/S的模式完成调用接口的。
优点:
- 简单并且易于理解(面向开发者)
- 轻量级的数据载体
- 高性能
缺点:
- 高耦合性
使用RPC意味着调用者要知道所调用接口的函数名、参数格式、参数顺序、参数名称等等详细信息。并且当接口改变的时候,调用者需要同步修改代码。
/listConversations
/listConversationDetail
REST
当前RESTful APIs已经成为了主流的接口解决方案了,相比较RPC,它是对Resource的模型化而非步骤,它是面向资源的。
以数据为中心,结合HTTP协议本身,后台构建对应资源的CURD。
优点:
- 利用了HTTP协议本身定义好了的状态动词,增强语义表现力
- 对系统的耦合程度低,调用者不再需要了解接口内部处理和实现细节
缺点:
- 缺少约束,缺少简单、统一的规范
- 有时候 payload 会变的冗余(overload),有时候调用api会比较繁琐( underfetching)
- overload
指当我们对用户用户请求的时候,我们可能只需要部分信息,但是REST风格的API会将全部信息传输给我们,这是一种浪费。这里其实提到的就是页面和数据库中的实体不一致的问题,面向这种问题,我们采取的措施可以有 前端处理(前端压力),加入新的传输对象
XXXDTO(随着业务的增多,java对象堆积严重),将无关数据设置为null(暴露字段) - underfetching 指我们需要 A用户 、B用户、C用户的信息,我们需要发送3个GET请求。 当我们打开网页的时候,如果是RestFul Application,可能我们会有很多个请求。
- overload
指当我们对用户用户请求的时候,我们可能只需要部分信息,但是REST风格的API会将全部信息传输给我们,这是一种浪费。这里其实提到的就是页面和数据库中的实体不一致的问题,面向这种问题,我们采取的措施可以有 前端处理(前端压力),加入新的传输对象
REST 解决的最大问题就是RPC中的耦合问题,它使前后端分离成为了可能。接口提供者在修改接口时,不容易造成breaking-change,接口调用者在调用接口时,往往面向数据模型编程,而省去了了解接口本身的时间成本。
GraphQL
GraphQL是近来比较热门的一个技术话题,相比REST和RPC,它汲取了两者的优点,即不面向资源,也不面向过程,而是面向数据查询(ask for exactly what you want)。同时GraphQL本身使用了强Schema来对数据模型进行定义,因此它具有较强的约束性。
优点:
- 网络开销低,可以在单一请求中获取REST中使用多条请求获取的资源 与Rest相对,如果是RESTful Application,可能请求数据就会马上有成百上千的HTTP Request,然而GraphQL的Application则可能只需要一两个,这相当于把复杂性和heavy lifting交给了server端和cache层,而不是资源有限,并且speed-sensitive的client端。
- 强类型Schema 约束意味着可以根据规范形成文档、IDE、错误提示等生态工具,也意味着校验的容易
- 特别适合图状数据结构的业务场景(比如好友、流程、组织架构等系统)
- 快速迭代的系统,往往要求对后端服务器公开数据的方式进行多次修改,以满足特定要求和设计要求,GraphQL可以避免这种方法,只有一个endPoint。
- 前端框架的异构使得构建和维护一个满足所有需求的API变得困难,使用GrapQL,每个客户端都能精确的访问所需的数据。
- 后端请求内容的精确定位,由于用户都精确的指明了自己感兴趣的信息,因此可以深入了解可用数据的范围。
缺点:
- GraphQL所带来的好处,大部分是对于接口调用者而言的,但是实现这部分的工作却需要接口提供者来完成,从而使接口提供者的兴奋程度并不大,对于一个全栈开发人员来说才是福祉所在。
- 业务逻辑模型是图状数据结构,比如社交。如果在一些业务逻辑模型相对简单的场景,使用GraphQL确实不如使用REST来得简单明了、直截了当。
What is?
GraphQL是一门查询语言,具体来说是一门API查询语言,同时他还是一个Schema语言,Schema Definition Language。 他能够对API进行查询,发现你能做些什么。就如官网中说到:
ask exactly what you want.
我们在使用REST接口时,接口返回的数据格式、数据类型都是后端预先定义好的,如果返回的数据格式并不是调用者所期望的,作为前端的我们可以通过以下两种方式来解决问题:
- 与后端沟通,修改接口
- 自己在前端做处理
如果是个人项目,后端接口可以随意更改,但是当存在多个客户端时,牵一发而动全身。我们只能自己在前端进行数据处理。因此如果接口的返回值,可以通过某种手段,从静态变为动态,即调用者来声明接口返回什么数据,很大程度上可以进一步解耦前后端的关联。
在GraphQL中,我们通过预先定义一张Schema和声明一些Type来达到上面提及的效果,我们需要知道:
- 对于数据模型的抽象是通过Type来描述的
- 对于接口获取数据的逻辑是通过Schema来描述的
Type
对于数据模型的抽象是通过Type来描述的,每一个Type有若干Field组成,每个Field又分别指向某个Type。 GraphQL的Type简单可以分为两种,一种叫做Scalar Type(标量类型),另一种叫做Object Type(对象类型)。
Scalar Type
GraphQL中的内建的标量包含,String、Int、Float、Boolean、Enum,对于熟悉编程语言的人来说,这些都应该很好理解。
值得注意的是,GraphQL中可以通过Scalar声明一个新的标量。
总之,我们只需要记住,标量是GraphQL类型系统中最小的颗粒,关于它在GraphQL解析查询结果时,我们还会再提及它。
Object Type
仅仅拥有标量是不能够抽象一些复杂的数据类型的,这时候我们需要使用对象类型。
type Article {
id: ID
text: String
isPublished: Boolean
}
当然这些对象可以进行嵌套
type Person {
id: ID
name: String
}
type Article {
id: ID
text: String
isPublished: Boolean
author: Person
}
除了嵌套之外,还可以声明各个模型之间的内在关联(一对多、一对一或多对多)。
Type 修饰
我们可以对类型进行修饰,包括List和Required。对应的语法是[Type]和Type!。
!的优先级高于[]
type Person {
id: ID!
name: String!
}
type Comment {
id: ID!
desc: String,
author: User!
}
type Article {
id: ID!
text: String
isPublished: Boolean
author: Person!
comments:[Comment!] //内部元素必填
}
Schema
Schema是用来描述对接口获取数据逻辑的,但这样描述仍然是有些抽象的,我们其实不妨把它当做REST架构中每个独立资源的uri来理解它,只不过在GraphQL中,我们用Query来描述资源的获取方式。因此,我们可以将Schema理解为多个Query组成的一张表。
Query包括三种操作:
- query(查询):当获取数据时,应当选取Query类型
- mutation(更改):当尝试修改数据时,应当使用mutation类型
- subscription(订阅):当希望数据更改时,可以进行消息推送,使用subscription类型
这里用REST模拟一套接口,Rest风格会存在多个endPoint。
GET /api/articles
GET /api/articles/:id
POST /api/articles
DELETE /api/articles/:id
PUT /api/articles/:id
PATCH /api/articles/:id
用GraphQL模拟一套接口,虽然存在多种请求,但是这里只会存在一个endPoint,\graphqls,由用户根据schema定义query决定实际需要的数据。
query {
articles(): [Article!]!
article(id: String): Article!
}
mutation {
createArticle(): Article!
updateArticle(id: String): Article!
deleteArticle(id: String): Article!
}
Resolver
如果我们仅仅在Schema中声明了若干Query,那么我们只进行了一半的工作,因为我们并没有提供相关Query所返回数据的逻辑。为了能够使GraphQL正常工作,我们还需要再了解一个核心概念,Resolver(解析函数)。
Query {
articles {
id
person {
name
}
comments {
id
desc
author
}
}
}
GraphQL在解析这段查询语句时会按如下步骤(简略版):
- 首先进行第一层解析,当前Query的Root Query类型是query,同时需要它的名字是articles
- 之后会尝试使用articles的Resolver获取解析数据,第一层解析完毕
- 之后对第一层解析的返回值,进行第二层解析,当前articles还包含三个子Query,分别是id、author和comments
- id在Author类型中为标量类型,解析结束
- author在Author类型中为对象类型User,尝试使用User的Resolver获取数据,当前field解析完毕
- 之后对第二层解析的返回值,进行第三层解析,当前author还包含一个Query, name,由于它是标量类型,解析结束
- comments同上…
我们可以发现,GraphQL大体的解析流程就是遇到一个Query之后,尝试使用它的Resolver取值,之后再对返回值进行解析,这个过程是递归的,直到所解析Field的类型是Scalar Type(标量类型)为止。解析的整个过程我们可以把它想象成一个很长的Resolver Chain(解析链)。
这里对于GraphQL的解析过程只是很简单的概括,其内部运行机制远比这个复杂,当然这些对于使用者是黑盒的,我们只需要大概了解它的过程即可。
当schema中定义的实体的部分字段与java定义的实体类型不一致的时候,我们需要单独定义resolver,匹配一致的时候就直接利用propertyDataFeathcer。
EntityResolver impements GraphQLResolver<Entity>{
难处理的字段名(){
//具体的操作
}
}
当然其java实体是不必须的,只是为了实现对应,推荐使用java实体,以此减少普通字段的resolver。
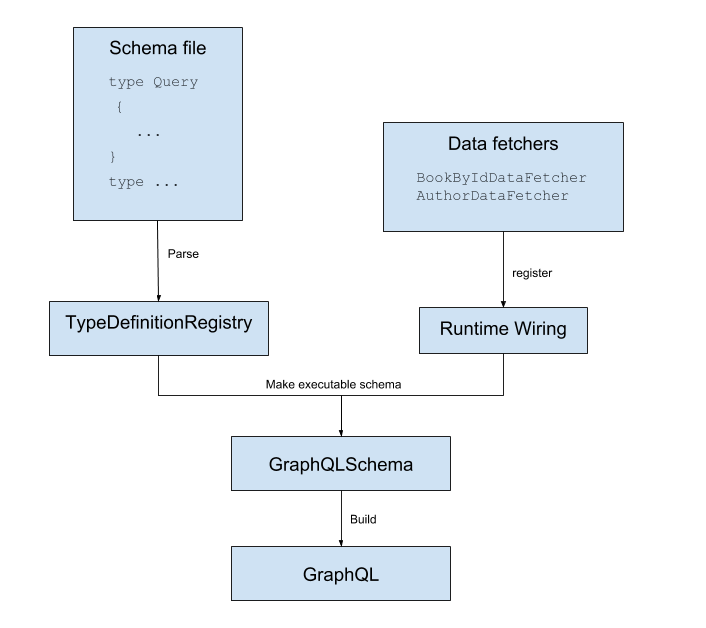
//解析SDL文件,生成TypeDefinitionRegistry
//注意query、mutation以及subscription要有对应的resolver implements GraphQueryResolver\GraphMutationResolver\GraphQLSubscriptionResolver
SchemaParser.newParser()
.file("schema.graphqls")
.resolvers(new Query(),new Mutation(),new EntityResolver())
.build()
.makeExecutableSchema();
注意这里我们是使用了
More
- 碎片
Fragment
type User {
name: String!
age: Int!
email: String!
street: String!
zipcode: String!
city: String!
}
fragment addressDetails on User {
name
street
zipcode
city
}
使用情景
如果是管理系统,推荐使用REST。这类API的特点如下:
- 关注对象与资源
- 存在多个不同的客户端
如果是Command和Action,推荐使用RPC。这类API的特点如下:
- 面向动作或指令
- 简单的交互
- 对系统性能要求较高
如果是Data API,这类API的特点是:
- 数据类型是具有图状的特点